Upload datasets
You can upload your own datasets to QFStudio to use them later in your job executions.
Datasets are securely stored in the platform and are available to all the users within your organization.
Info
Datasets are spcific for a Use Case and must follow the use case’s JSON input data format.
Create a dataset for the Portfolio Optimization use case#
The input data for any job in QFStudio must be in JSON format.
This JSON format description for the Portfolio optimization use case is defined in the Technical details tab of the use case details page.
Example files#
A dataset for this use case would look like this one:
{
"returns": [
0.01139880743655387,
-0.03136492406079324,
-0.049502245361288416,
...
],
"resolution": 0.01,
"max_investment_per_asset": 0.15,
"investment_bands": [ [ ... ], [ ... ], ... ],
"risk_aversion": null,
"target_volatility": 0.015,
"covariances": null,
"correlations": [ [ ... ], [ ... ], ... ],
"volatilities": [ ... ],
"constraints": [
{
"linear": [ ... ],
"constant": 0.0,
"operator": ">=",
"penalty_strength": 100
}
]
}
Description of the input format#
The input data format requires the following parameters:
- returns (array): Returns of the assets. The assets can be identified by either name or index.
- resolution (number): Resolution of the discretization.
- max_investment_per_asset (number): Max investment per asset
- investment_bands (array): Investment bands set by the user for each asset. Each investment band represents the minimum and maximum value.
- target_volatility (number): Target volatility parameter indicating the desired risk of the portfolio.
- correlations (array): Correlations of the assets. The assets can be identified by either name or index. If set, volatilities must also be set but covariances must not be set.
- covariances (array): Covariances of the assets. The assets can be identified by either name or index. Should not be used when correlations and volatilities and set.
- volatilities (array): Volatilities of the assets. The assets can be identified by either name or index. If set, correlations must also be set but covariances must not be set.
- constraints (array): The constraints of the portfolio provided as a list.
- risk_aversion (number): The risk aversion parameter indicating the desired risk-reward balance.
This table shows the different fields that shall be included in an input dataset:
| Field | Type | Required | Possible values |
|---|---|---|---|
returns |
array | yes | |
resolution |
float | yes | One of these values: 0.1, 0.01, 0.001 |
max_investment_per_asset |
float | yes | Max investment per asset allowed. Must be in the range [0.0, 1.0]. |
investment_bands |
array | yes | Array of pairs with minimum and maximum values. Use null for no bound. |
target_volatility |
float | no | View example files above |
correlations |
array | no | View example files above |
covariances |
array | no | View example files above |
volatilities |
array | no | View example files above |
constraints |
array | no | View example files above |
risk_aversion |
float | no | View example files above |
Create a dataset for the Index Tracking user case#
The input data for any job in QFStudio must be in JSON format.
This JSON format description for the Index Tracking use case is defined in the Technical details tab of the use case details page.
See the following subections for more details.
Example files#
A dataset for this use case would look like this one:
{
"action": "optimize",
"index": "Nasdaq-100",
"period": {
"start": "2023-01-01",
"end": "2023-04-30"
},
"asset_number": 50,
"resolution": 0.01,
"investment_band": [
null,
0.5
],
"excess_return_ratio": null
}
Or like this one:
{
"action": "track_out_of_sample",
"index": "Nasdaq-100",
"period": {
"start": "2023-05-12",
"end": "2023-05-19"
},
"resolution": 0.01,
"holdings": {
"AAPL": 0.03,
"ADSK": 0.01,
"AEP": 0.01,
"AMD": 0.02,
"ANSS": 0.07,
...
}
}
Description of the input format#
This are the high level parameters of the input data:
- action: The ‘optimize’ action refers to obtaining a tracking portfolio using all the provided information and constraints. The ‘track_out_of_sample’ action refers to testing the performance of an output portfolio (obtained by performing the ‘optimize’ action first) on a custom period of time.
- index: The index to track.
- perio: If ‘action’ is ‘optimize’, this refers to the tracking period at which the index is wished to be tracked. If ‘action’ is ‘track_out_of_sample’, this refers to the period for which one wishes to see the selected portfolio’s performance.The earliest and latest supported dates are 2021-01-04 and 2023-06-09.
- asset_number: The number of assets under management (which are components of the index) to use in the final portfolio.
- resolution: The resolution of the asset weight percentages.
- investment_band: Applicable for the ‘optimize’ action. The lower and upper bounds of the percentage of the portfolio that each asset can represent. If null at the first element the lower bound will be set as one unit of the resolution, and if null at the second element the upper bound will be set to 1 (100%).
- excess_return_ratio: Applicable for ‘optimize’ action. The float between 0 and 1 representing the ratio between optimizing for a faithful tracking of the index, or obtaining an alpha or excess return. The bigger the number, the more the optimization will try to maximize returns over tracking the index. If None, the optimization will aim for a faithful tracking of the index. Currently, this is supported for the Nasdaq-100 index.
- holdings: Applicable for ‘track_out_of_sample’ action. Stock holdings of the optimized tracking portfolio. The number is the percentage of the portfolio that the corresponding stock represents. Should be taken from the ‘holdings’ field of the output of an ‘optimize’ job.
This table shows the different fields that shall be included in an input dataset:
| Field | Type | Required | Possible values |
|---|---|---|---|
action |
string | yes | "optimize" or "track_out_of_sample" |
index |
string | yes | "^NDX", "NDX", "Nasdaq-100", "^GSPC", "SPX" or "S&P 500" |
period |
object | yes | An object with two dates "start" and "end" in YYYY-MM-DD format |
resolution |
number | yes | One of these: 0.1, 0.05, 0.01 |
asset_number |
integer | no | An integer number greater than 0 |
investment_band |
array | no | Array of two items between 0.0 and 1.1. Example: [0.5, 0.5] |
excess_return_ratio |
number | no | A number between 0.0 and 1.0 |
holdings |
object | no | View example files above |
Full input JSON schema#
This is the input JSON Schema for Index Tracking use case. Here is all the information you need to create input datasets for this use case:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"definitions": {
"period": {
"type": "object",
"properties": {
"start": {
"type": "string",
"format": "date"
},
"end": {
"type": "string",
"format": "date"
}
},
"required": ["start", "end"]
}
},
"type": "object",
"description": "This is the JSON Schema for Index Tracking, powered by Singularity. Please see individual property descriptions for more details on their use. In index tracking, the focus is on replicating the performance of a specific market index by constructing a portfolio that closely tracks its returns. This approach aims to provide investors with an investment strategy that mirrors the index’s performance, allowing them to gain exposure to a broad market without needing to manage all the individual assets in the index. Using the package, users input the relevant information for the target market index they wish to track, including a limitation on the target number of assets under management. Additional optional settings, such as weighting constraints, risk preferences, or enhanced performance (alpha), can also be specified. The result of the index tracking process is a set of asset weights calibrated to replicate the returns of the target index as closely as possible (or to outperform it).",
"properties": {
"action": {
"type": "string",
"enum": ["optimize", "track_out_of_sample"],
"description": "The 'optimize' action refers to obtaining a tracking portfolio using all the provided information and constraints. The 'track_out_of_sample' action refers to testing the performance of an output portfolio (obtained by performing the 'optimize' action first) on a custom period of time."
},
"index": {
"type": "string",
"enum": ["^NDX", "NDX", "Nasdaq-100", "^GSPC", "SPX", "S&P 500"],
"description": "The index to track."
},
"period": {
"$ref": "#/definitions/period",
"description": "If 'action' is 'optimize', this refers to the tracking period at which the index is wished to be tracked. If 'action' is 'track_out_of_sample', this refers to the period for which one wishes to see the selected portfolio's performance.The earliest and latest supported dates are 2021-01-04 and 2023-06-09."
},
"asset_number": {
"type": "integer",
"description": "The number of assets under management (which are components of the index) to use in the final portfolio."
},
"resolution": {
"type": "number",
"enum": [0.1, 0.05, 0.01],
"description": "The resolution of the asset weight percentages."
},
"investment_band": {
"type": "array",
"minItems": 2,
"maxItems": 2,
"items": {
"anyOf": [
{
"type": "number",
"minimum": 0.0,
"maximum": 1.0
},
{
"type": "null"
}
]
},
"description": "Applicable for the 'optimize' action. The lower and upper bounds of the percentage of the portfolio that each asset can represent. If null at the first element the lower bound will be set as one unit of the resolution, and if null at the second element the upper bound will be set to 1 (100%)."
},
"excess_return_ratio": {
"anyOf": [
{
"type": ["number", "null"],
"minimum": 0.0,
"maximum": 1.0
}
],
"description": "Applicable for 'optimize' action. The float between 0 and 1 representing the ratio between optimizing for a faithful tracking of the index, or obtaining an alpha or excess return. The bigger the number, the more the optimization will try to maximize returns over tracking the index. If None, the optimization will aim for a faithful tracking of the index. Currently, this is supported for the Nasdaq-100 index."
},
"solver": {
"type": "string",
"enum": ["Classical", "D-Wave_Leap_Hybrid"],
"description": "Applicable for 'optimize' action."
},
"holdings": {
"type": "object",
"additionalProperties": { "type": "number" },
"description": "Applicable for 'track_out_of_sample' action. Stock holdings of the optimized tracking portfolio. The number is the percentage of the portfolio that the corresponding stock represents. Should be taken from the 'holdings' field of the output of an 'optimize' job."
}
},
"required": ["action", "index", "period", "resolution"],
"additionalProperties": false
}
Create a dataset for the Derivative Pricing use case#
The input data for any job in QFStudio must be in JSON format.
This JSON format description for the Derivative Pricing use case is defined in the Technical details tab of the use case details page.
Example files#
A dataset for this use case would look like this one:
{
"exercise_type": "Option",
"dimensionality": 1,
"terminal_condition": "Call",
"prices_reducer": "Max",
"pde_model": "Black_Scholes",
"exercise_style": "European",
"pde_model_parameters": {
"initial_prices": [
5
],
"volatilities": [
5
],
"dividends": [
5
],
"interest_rate": 2,
"strike_price": 9
},
"exercise_style_parameters": {
"maturity_time": 3
}
}
Description of the input format#
The input data format requires the following parameters:
- exercise_type (string): The exercise type refers to the type of the derivative.
- dimensionality (number): The dimensionality defines how many asset your derivative relies on. It is specified as a positive integer.
- terminal_condition (string): The terminal condition defines what does “exercising the right of the contract” mean. The common ones are Put and Call. The terminal condition is defined by a string.
- prices_reducer (string): Only relevant for a basket option, i.e. when the derivative relies on more than one assets. It defines how a basket option price is computed out of each individual asset price in the basket.
- pde_model (string): The PDE model defines the partial differential equation that defines the evolution of the price.
- exercise_style (string): The exercise style defines how the option holder can exercise their rights.
- pde_model_parameters (object): The PDE model parameters are the parameters necessary to completely define the evolution of the prices.
- exercise_style_parameters (object): The parameters for the exercise style.
This table shows the different fields that shall be included in an input dataset:
| Field | Type | Required | Possible values |
|---|---|---|---|
exercise_type |
string | yes | "Option" |
dimensionality |
number | yes | A positive integer |
terminal_condition |
string | yes | "Put" or "Call" |
prices_reducer |
string | yes | "Min" or "Max" |
pde_model |
string | yes | View example files above |
exercise_style |
string | yes | View example files above |
pde_model_parameters |
object | yes | View example files above |
exercise_style_parameters |
object | yes | View example files above |
Create a dataset for other use case#
The input data for any job in QFStudio must be in JSON format.
This JSON format description for each user case is defined in the Technical details tab of the use case details page.
In that section you will find both the input and the output formats.
Datasets are input data for the jobs, so only the input data format is relevant in this point.
To create a dataset for a given use case follow these steps:
- Create an empty JSON file.
{}
- Add all the specified parameters in the first level of your JSON file, they are all required fields:
{
"param_1_stirng": "this is a string",
"param_2_number": 25,
"param_3_number": 0.5,
"param_4_array": ["an", "array", "with", "your", "values"],
"param_4_oject": {"nested_param": "follow the use case instructions for nested objects format"},
"param_4_boolean": true
}
Info
There are five parameter types allowed: string, number, array, object and boolean.
Upload a dataset:#
Once you have created your JSON file following the use case input format, you can upload it to QFStudio through the Datasets section.
- Go to the Datasets section through the left side menu
-
Then, on the top-right corner, click on the Upload dataset button
-
You will get the upload file page with the following fields:
- Use Case Select the use case related to this dataset
- Name Write a name for this file. Use readable/accessible names that help you identify your files
- Description Write a description of the file to help you identify it from other files
- Data file Browse the data file itself from your computer in JSON format
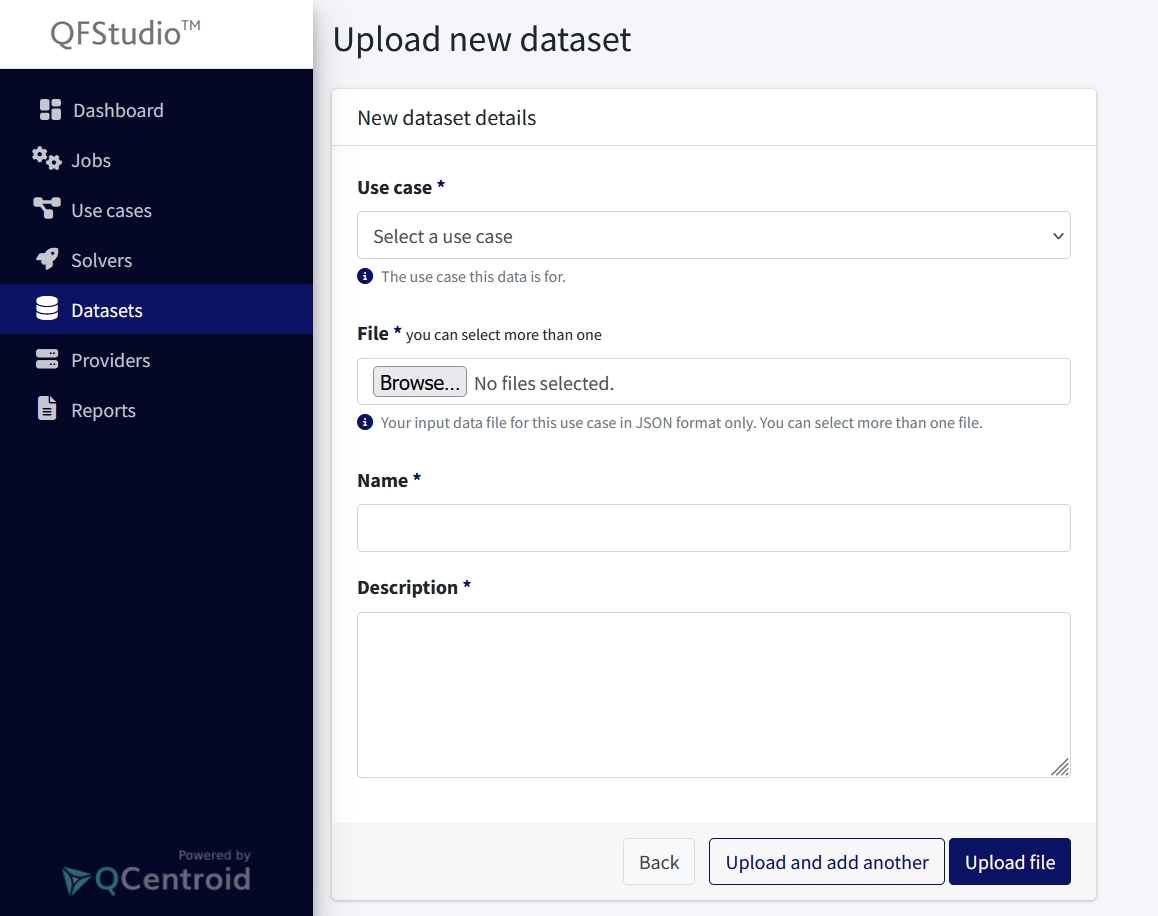
- Click the Upload file button
Now the new file will be listed in the Data files section as will be available as input for your jobs.
Info
The file format will be validated on upload and the file will be rejected if it does not comply with the use case input data specification.